









Python では、XNUMX 行の終わりをマークして新しい行を開始するには、特殊文字を使用する必要があります。 同時に、さまざまな Python ファイルを操作するときに正しく使用する方法を理解し、必要なときにコンソールに表示することが重要です。 プログラムコードを操作する際に改行の区切り記号を使用する方法、それを使用せずにテキストを追加できるかどうかを詳細に理解する必要があります。
改行文字に関する一般情報
n は、Python で情報を新しい行で折り返し、古い行を閉じるための記号です。 この記号は、次の XNUMX つの要素で構成されています。
- 逆斜め;
- n は小文字です。
この文字を使用するには、「print(f" HellonWorld!")」という表現を使用できます。これにより、f ラインで情報を転送できます。
印刷機能とは
追加設定なしでは、次の行へのデータ転送文字は非表示モードで追加されます。 このため、特定の機能を有効にしないと、行間で見ることができません。 プログラム コードでセパレータ アイコンを表示する例:
印刷 (「Hello, World」!」) – 「Hello, World!」n
同時に、この性格のそのような発見は、Pythonの基本的な特性に書かれています。 「print」関数には、「end」パラメータのデフォルト値 – n があります。 この文字を行末に設定して次の行にデータを転送するのは、この機能のおかげです。 「印刷」機能の説明:
print(*objects, sep=' ', end='n', file=sys.stdout, flush=False)
「print」関数の「end」パラメータの値は、文字「n」と同じです。 プログラムコードの自動アルゴリズムに従って、最後に行を完成させ、その前に「印刷」関数を記述します。 単一の「印刷」機能を使用すると、画面に XNUMX 行しか表示されないため、その作業の本質に気付かない場合があります。 ただし、次のようなステートメントをいくつか追加すると、関数の結果がより明確になります。
print("Hello, World 1!") print("Hello, World 2!") print("Hello, World 3!") print("Hello, World 4!")上記のコードの結果の例:
こんにちは、ワールド1です! こんにちは、ワールド2です! こんにちは、ワールド3です! こんにちは、ワールド4です!
改行文字を print に置き換える
「印刷」機能を使用すると、行間に区切り文字を使用しないようにすることができます。 これを行うには、関数自体の「end」パラメーターを変更する必要があります。 この場合、「終了」値の代わりにスペースを追加する必要があります。 このため、「終わり」の文字を置き換えるのはスペースです。 デフォルト設定が設定された結果:
>>> print("Hello") >>> print("World") Hello World文字「n」をスペースに置き換えた後の結果の表示:
>>> print("Hello", end=" ") >>> print("World") Hello World文字を置換するこの方法を使用して、一連の値を XNUMX 行に表示する例:
for i in range(15): if i < 14: print(i, end=", ") else: print(i)
ファイルで区切り文字を使用する
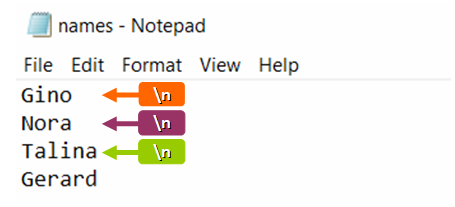
プログラムコードのテキストが次の行に転送される記号は、完成したファイルにあります。 ただし、そのような文字はデフォルトで非表示になっているため、プログラム コードを介してドキュメント自体を表示しないと、ドキュメントを表示することはできません。 改行文字を使用するには、名前を入力したファイルを作成する必要があります。 開くと、すべての名前が改行で始まることがわかります。 例:
names = ['Petr', 'Dima', 'Artem', 'Ivan'] with open("names.txt", "w") as f: for name in names[:-1]: f.write(f "{name}n") f.write(names[-1])名前は、テキスト ファイルが情報を別々の行に分けるように設定されている場合にのみ、この方法で表示されます。 これにより、前の各行の末尾に隠し文字「n」が自動的に設定されます。 隠された記号を見るには、関数「.readlines()」を有効にする必要があります。 その後、すべての非表示の文字がプログラム コードの画面に表示されます。 関数のアクティブ化の例:
open("names.txt", "r") を f として: print(f.readlines())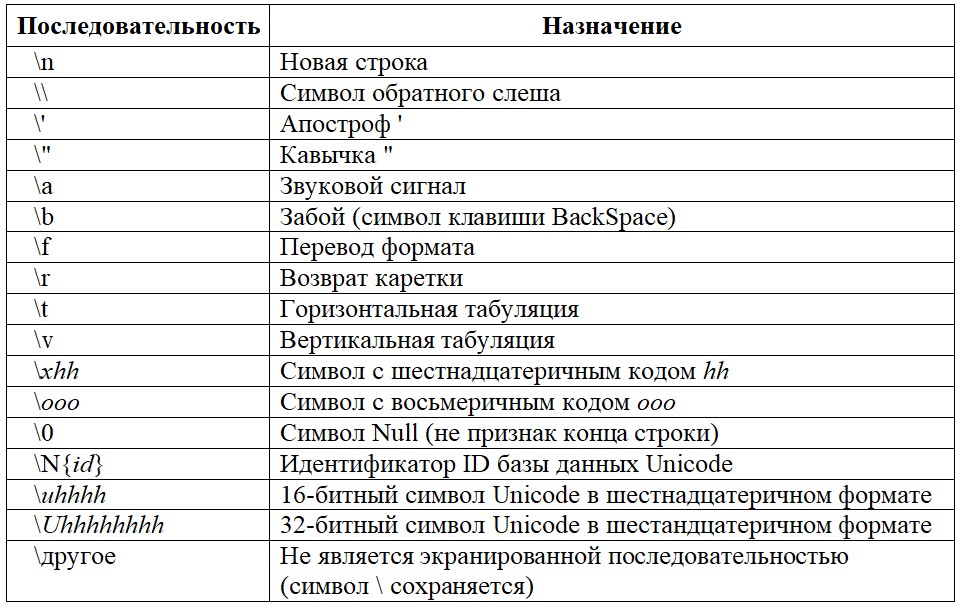
助言! Python を積極的に使用していると、プログラム コードを XNUMX 行にまとめて書かなければならない状況に遭遇することがよくありますが、それを見直して不正確さを分離せずに特定することは非常に困難です。 長い行を別々のフラグメントに分割した後、コンピューターがそれを全体と見なすように、値の間の空きスペースごとに、文字「」-バックスラッシュを挿入する必要があります。 文字を追加したら、別の行に移動してコードを書き続けることができます。 起動時に、プログラム自体が個々のフラグメントを XNUMX 行にまとめます。
文字列を部分文字列に分割する
XNUMX つの長い文字列を複数の部分文字列に分割するには、split メソッドを使用できます。 それ以上編集しない場合、デフォルトの区切り文字はスペースです。 このメソッドを実行した後、選択されたテキストは部分文字列によって個別の単語に分割され、文字列のリストに変換されます。 例として:
string = "some new text" 文字列 = string.split() print(strings) ['some', 'new', 'text']
部分文字列のリストを XNUMX つの長い文字列に変換する逆変換を実行するには、join メソッドを使用する必要があります。 文字列を操作するためのもう XNUMX つの便利な方法は、strip です。 これにより、行の両側にあるスペースを削除できます。
まとめ
Python で作業しているときに新しい行から特定のデータを出力するには、古い行を文字「n」で終了する必要があります。 その助けを借りて、記号の後の情報は次の行に転送され、古い行は閉じられます。 ただし、このシンボルを使用してデータを転送する必要はありません。 これを行うには、パラメーター end = " を使用できます。